Model Notes
Model 1: Naive Bayes
For fast deployment, we initially used TextBlob, which is a simple Naive Bayes sentiment model. Naive Bayes is a simple probablistic algorithm. It basically calculates the probability of a sentence being negative based on whether the words in that sentence typically appear in negative or positive sentences.
For example, if 80% of training data with the word "stupid" end up being negative, "stupid" will be classified as negative, and any test sentence with the word "stupid" will have that negative weight
The test sentence sentiment is based on which sentiment the words most lean toward
It's a naive algorithm because it assumes word meanings are independent, which isn't that true. For example, "pretty" is a posoitive word, "stupid" is a negative word, but "pretty stupid" is especially negative.
It's light and easy to deploy'
Model 2: Keras Neural Network Model
This model used an Embedding layer and a simple Dense neural network to classify sentiment. It captures some word relationships via embeddings but doesn't model temporal dependencies
Architecture
Embedding layer: turns word indicies into dense word vectors, which captures semantic meanings, and doesn't treat words as independent
GlobalAveragePooling1D: Summarizes the word embeddings of a sentence into a single vector.
Dense layers: Fully connected layers that learn to map the summarized vector to a sentiment prediction.
Dropout layer: Helps prevent overfitting by randomly deactivating some neurons during training.
Word embedddings allows the model to have a strong understanding of words compared to Naive Bayes
However, it lacks a sequential context (word order), so like "not good" and "good not" would mean the same thing
Also doesn't model how a word can change on its surrounding context"
Model 3: PyTorch LSTM
Instaed of pooling, this model uses an LSTM, which is a type of RNN designed to capturing sequential information across the word sequence, which is good for sentiment analysis, where context is important
More computationally intensive but captures more complex dependencies. to be expanded later.
Model 3 Optimization
When I initially tested the model, I noticed that up to E3, train accuracy increased and validation loss decreased
After that, train accuracy improves, but validation loss increased, which indicates overfitting. So 3 epochs is the best
However, when I looked at the confusion matrix, the false positives was extremely high, indicating poor fitting in general. I looked at the model and noticed vocabulary was 4000, which is pretty low for vocabulary. Increasing it to 50000 vastly increased accuracy and pushed the overfitting issue back.
I tested vocab = 40000 and 30000, will later automate this but 30000 was better, with accuracy over 89% at decreasing validation loss on epoch 6
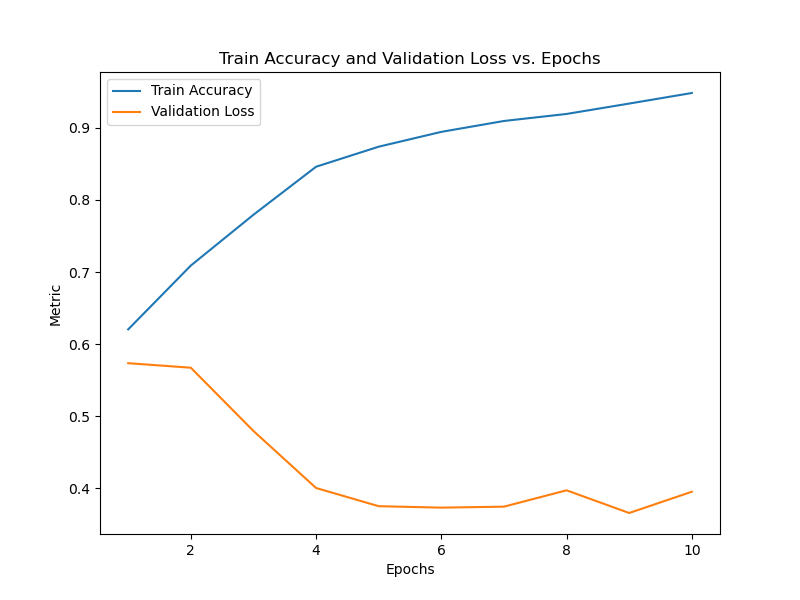
It's hard to see, but based on the numbers:
Epoch 1/10, Train Accuracy: 0.6205, Validation Loss: 0.5736
Epoch 2/10, Train Accuracy: 0.7090, Validation Loss: 0.5674
Epoch 3/10, Train Accuracy: 0.7794, Validation Loss: 0.4797
Epoch 4/10, Train Accuracy: 0.8460, Validation Loss: 0.4006
Epoch 5/10, Train Accuracy: 0.8739, Validation Loss: 0.3753
Epoch 6/10, Train Accuracy: 0.8944, Validation Loss: 0.3733
Epoch 7/10, Train Accuracy: 0.9095, Validation Loss: 0.3747
Epoch 8/10, Train Accuracy: 0.9193, Validation Loss: 0.3974
Epoch 9/10, Train Accuracy: 0.9336, Validation Loss: 0.3659
Epoch 10/10, Train Accuracy: 0.9483, Validation Loss: 0.3954
I plan to further improve the model thro optimizer parameters, test/train split, etc - later. I'll probably also run it a few times and take an average of epoch values instead of only one time, but LSTMs are slow so - later.